
Communicating with an API using C++
Asynchronous and Streaming API
The Rev.ai automated text-to-speech suite consists of 2 APIs for processing media files: the Asynchronous API and the Streaming API. The Asynchronous API allows pre-recorded audio or video files to be transcribed via an HTTP POST request. Using the Asynchronous API an hour-long recording can be processed in a matter of minutes. The Streaming API allows real-time transcription of an audio or video feed. The Streaming API uses WebSockets to allow duplex communication over a single TCP connection.
Get an access token
The API exposes RESTful endpoints that are used to perform tasks such as submit media to be transcribed and retrieve transcriptions. To use the Rev.ai API an access token is needed. To sign up for an access token create an account at https://rev.ai. Click on the Access Token and generate a new token. The access token should be sent as a header in a request sent to the API in the format Authorization: Bearer <rev_access_token>.
C++Rest SDK
To communicate with the API we will use Microsoft’s C++Rest SDK. The C++Rest SDK is an open-source library that allows C++ applications to communicate with a RESTful service or Websockets over a TCP connection. Information on how to install the SDK and include it in a C++ application can be found at https://github.com/Microsoft/cpprestsdk.
Asynchronous Example
Create a Job
The following example will show how to use the asynchronous API to transcribe a sample audio file. Submitting a file to be transcribed by the asynchronous speech-to-text engine is known as a job. A job is created by sending an HTTP Post request to the URL https://api.rev.ai/speechtotext/v1/jobs.The request should include the Content-Type header that defines the format of the body of the request. For this example, we will use the application/json Content-Type which allows us to define a file located at a URL to transcribe.
If we wanted to upload a file we would set the Content-Type header to multipart/form-data. Typically we would define a callback_url in our initial request that listens for an HTTP Post message when the transcription processing is complete. To keep this example simple we will use polling to determine when the processing is complete. Polling is not recommended in a production environment but since the file we are trying to transcribe is relatively short we will poll the server every few seconds to determine when the job has been completed.

Get JobID
The request will respond with a JSON object containing the id of the job that is being processed. The job id will be used to poll the status of the job and to retrieve the transcription when processing is complete.

Poll for Processing Completion
To poll the server we will send a GET request every 5 seconds to the URL https://api.rev.ai/speechtotext/v1/jobs/<jobID>. The response will be a JSON object containing the processing status of the job. When the processing status is transcribed the transcription is ready to be retrieved.

Get the Transcript
When the processing status is transcribed the transcription can be retrieved by sending a GET request to the URL https://api.rev.ai/speechtotext/v1/jobs/<jobID>/transcript. The format of the response is determined by the value in the Accept header that is sent in the request. If the value is text/plain the response will return the transcription in plaintext format. The value application/vnd.rev.transcript.v1.0+json is used to return a JSON formatted transcription. Although application/vnd.rev.transcript.v1.0+json is JSON, C++Rest SDK does not recognize it as a JSON Content-Type. To circumvent this we create a handler for the response that changes the Content-Type to application/json.

Simulate Captioning
The JSON formatted response contains additional information such as speaker segmentation, punctuation, and word-level timestamps. Using the word-level timestamps we can simulate captioning.

How to Use the Rev AI Streaming API
The following example will show how to use the streaming API to transcribe a sample audio file. The streaming API uses the WebSocket protocol to allow duplex communication across a single TCP connection. The API receives binary audio and returns recognized speech content in JSON format.
Connect to the Web Socket
To connect to the Streaming API a WebSocket connection is made to the following URL, wss://api.rev.ai/speechtotext/v1/stream. The URL must also include your access token and the content type as URL parameters. The API accepts the following audio formats: raw audio, flac, and wav. For this example, we will send a wav file.

Send/Receive Data
The API will send JSON formatted messages containing a type property to indicate the type of response that is being sent. The type property will contain one of three values: connected, partial and final.
When the type property is connected this indicates the WebSocket connection has been made and the API is ready to receive the binary data.
The remaining response types will be either partial or final. These responses contain speech content and the response type indicates the state of the content. For this example, we will only process final response types that indicate the final hypothesis for the speech content. For simplicity, we will output the words from these responses as they are received.

Close Connection
When all of the binary data has been sent or the streaming has ended send the message EOS to the API to indicate streaming is finished. This is the only text formatted message that can be sent to the API.

Once this message is received the API will send its final transcription results and close the connection. Once a close connection is received from the API we can close the connection on our end and exit the application.

What Is Speech-to-Text?
Over the past few years, the rise of virtual assistants has made talking to computers more commonplace. Whether it’s turning on your lights with your voice or telling your mobile phone to navigate you to your destination, talking to computers has become more integrated into our everyday lives. Although having a computer respond to commands that are spoken to it may be a new way of life, the technology behind computers being able to translate human speech has been around for many years.
The technology that takes a human’s spoken words and translates them to text is known as Automatic Speech Recognition or ASR. The first speech recognition system named “Audrey” was created by Bell Laboratories in 1952 and could only recognize digits. IBM created the first word recognition system 10 years later in 1962. The system was named “Shoebox” and could understand 16 English words. Today speech recognition is used far more than people realize. Video captions are a great example of practical ASR use in our everyday lives.
Rev AI
With over 150 million transcriptions completed, Rev is one of the leaders in speech-to-text services. Transcriptions, captions, and subtitles are a few of the many speech-to-text services that we provide. Rev AI is our automated speech recognition service that allows developers to connect to our speech-to-text engine within their applications. Some of the many ways that Rev AI is being used include the following:
- Providing closed captioning for live video streams
- Reviewing/searching podcast audio
- Transcribing depositions
- Transcribing audio & video libraries
Why use the Rev AI Speech Recognition API for Java?
Accuracy
Accuracy is important when providing automated services. For ASRs a key measurement of accuracy is the Word Error Rate (WER). WER is measured by the number of errors divided by the total number of words. Errors include words incorrectly transcribed, additional words that were added, and words that were omitted. The lower the WER the more accurate an ASR is. Rev AI has the lowest WER among its competitors.
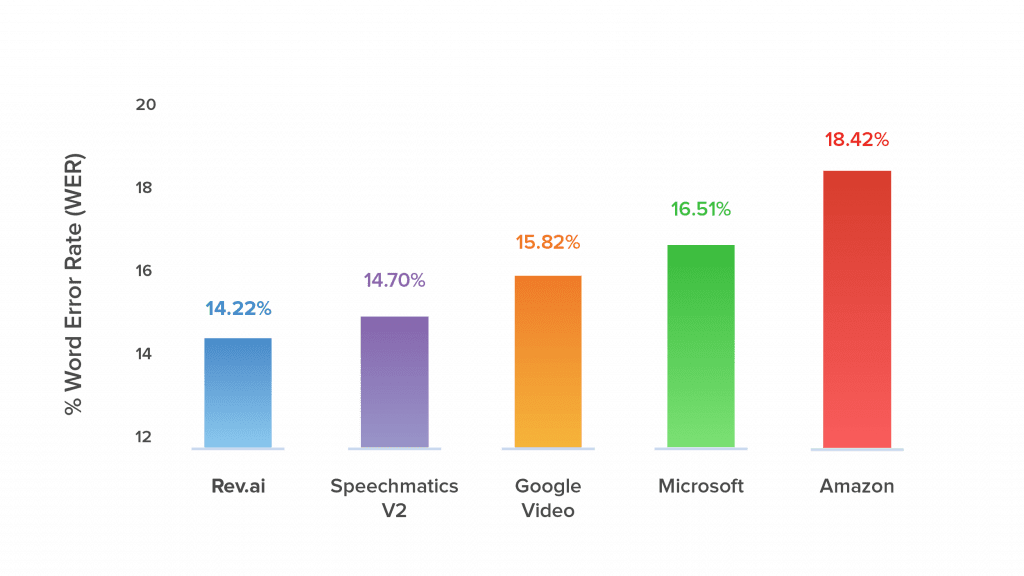
Ease of Use
There is no need to learn some new proprietary format. Interacting with the API is as simple as sending an HTTP request. The API responds with either plaintext or JSON.
Security
Communication with the API is encrypted both in transit and at rest. You are also given control of your data. Data can be deleted through an API endpoint or deletion policies can be created from the web application. When tighter controls are necessary, the on-premise solution allows you to run the speech-to-text engine in your own private instance.
Pricing
The first 5 hours of speech-to-text translation are free which is more than sufficient enough to test drive the API. After that, it’s $0.035 per minute of speech processed rounded to the nearest 15 seconds. An hour-long audio file would cost approximately $2.10.
Constantly Improving
Rev AI is always improving its accuracy as it gathers data and improves its speech recognition system. See how Rev AI has improved over time in the last 4 years:






