




Automatic Speech Recognition Transcription Models Explained
Automatic speech recognition is faster and more accurate than ever before, thanks in part to technology improvements in speech recognition models.


Automatic speech recognition, which involves using a computer to transcribe human speech, has always been a classic problem in technology. Classically it fell within the domain of signal processing, but today state of the art methods utilize machine learning to achieve fantastic results.
As early as 1952, the famous AT&T Bell Laboratories released a system called “Audrey” which was capable of identifying numeric digits spoken by a single voice. Later in the ‘80s, the Hidden Markov Model allowed for the development of systems which could identify thousands of spoken words. However, the accuracy still left something to be desired.
Yet, in the past 5 or so years, the deep learning revolution has sent speech recognition into a new golden era, allowing for more rapid and accurate speech transcription than ever before.
Current speech to text models rely heavily on recurrent neural networks along with a few other tricks thrown in. RNNs are useful because they were designed to deal with sequences, and human speech involves sequences of word utterances. The RNN architecture allows the model to attend to each word in the sequence and make predictions on what might be said next based on what came before. This, along with the raw acoustic waveforms and the words they suggest, allow models to accurately transcribe speech.
The Acoustic Model
As mentioned, one of the key components of any ASR system is the acoustic model. This model takes as input the raw audio waveforms of human speech and provides predictions at each timestep. The waveform is typically broken into frames of around 25 ms and then the model gives a probabilistic prediction of which phoneme is being uttered in each frame. Phonemes are like the atomic units of pronunciation. They provide a way of identifying the different sounds associated with human speech.
Many different model types have been used over the years for the acoustic modelling step. These include the Hidden Markov Model, Maximum Entropy Model, Conditional Random Fields, and Neural Networks.
Part of what makes acoustic modeling so difficult is that there is huge variation in the way any single word can be spoken. The exact sounds used and the exact characteristics of the waveform depend on a number of variables such as the speaker’s age, gender, accent, emotional tone, background noise, and more.
Thus, while a naively trained acoustic model might be able to detect well-enunciated words in a crystal clear audio track, it might very well fail in a more challenging environment. This is why it’s so important for the acoustic model to have access to a huge repository of (audio file, transcript) training pairs. This is one reason why Rev’s automatic speech recognition excels. It has access to training data from years of work of 50,000 native English speaking transcriptionists and the corresponding audio files.
Acoustic models also differ between languages. An acoustic model used for English, for example, can’t be used for German. However, if the two languages have some vocal similarities, as these two do, then engineers can use a technique called transfer learning to take the original model and transfer it to the new language.
This process involves taking the pretrained weights from the original model and fine tuning them on a new dataset in the target language. Transfer learning is a relatively new idea that’s been used extensively in computer vision and NLP and has now made its way to the speech recognition field.
The Language Model
The second part of the automatic speech recognition system, the language model, originates in the field of natural language processing. The core goal in language modeling is, given a sequence of words, to predict the next word in the sequence. Normally language modeling is done at the word level, but it can also be done at the character level which is useful in certain situations such as for languages that are more character based (Chinese, Japanese, etc.).
RNNs are the tool of choice in language modeling, specifically things like LSTMs, GRUs, and Transformers. While an ASR system could technically operate successfully without access to a language model, doing so highly limits its accuracy. This is because the acoustic model can often confuse two or more similar sounding words.
For example, if it identifies that the speaker has just said “I walked around the ___” and it identifies that the next word should be either “clock” or “block” but it can’t decide which, then the acoustic model can defer to the language model for the final decision. The language model can definitively decide that, in this context, the word “block” makes much more sense. However, if the sentence had been “I worked around the ___”, then “clock” would be the natural choice. Thus the language model provides invaluable expertise in terms of teasing out these nuances when the acoustic model is not confident in its decisions.
Types of Speech Recognition Models
Connectionist Temporal Classification
One of the more “classical” types of deep speech recognition models is connectionist temporal classification. This model type was designed to address one of the key problems associated with training a speech recognition model, that of somehow aligning the audio clip with the text transcript. More formally, let’s say you have an input sequence X = [x1, …, xn] and a set of labels Y = [y1, …, ym].
You can see here that both X and Y are variable length, determined by things like the sampling rate (for X) and the number of words in the speech (for Y). For any pair of Y and X, CTC gives a method to compute the conditional probability p(Y|X) and then to infer the optimal solution by taking Y* = argmax_Y P(Y|X).
The details of the CTC method are relatively complex, but the general idea is simple. The algorithm is alignment free, meaning it doesn’t require an alignment between audio and text. In order to compute the overall probability, P(Y|X), it first computes time step probabilities P(a_t | X) of a given alignment between X and Y at time step t. It typically uses an RNN architecture to compute these probabilities.
It then sums over (marginalizes out) the products of these time step alignments to produce an overall probability P(Y | X). While this process would typically be very time intensive since the space of all possible alignments is so vast, in practice it is feasible due to the use of a clever dynamic programming algorithm to sum over all alignments.
Listen, Attend, Spell
One recent successful model that came out of Google Brain and Carnegie Mellon University is the Listen, Attend, Spell model. This model uses a recurrent neural network encoder as the acoustic model and an attention based recurrent decoder as a character level language model.
This is fundamentally a sequence-to-sequence model as it converts a sequence of audio waves into a sequence of text characters. The recurrent decoder is a bidirectional LSTM with a pyramid structure, i.e. decoders are stacked such that subsequent layers have reduced time resolution.
Convolutional Architectures
While recurrent layers are quite popular, convolutional neural networks have their place in speech recognition models as well. In a 2016 paper out of MIT, Carnegie Mellon, and Google Brain, the authors utilize a hybrid approach which combines convolutional and recurrent methods. Convolutional techniques are advantageous in that they use weight sharing (shared weight filters) and pooling operations that not only improve the robustness of the network but drastically reduce the number of parameters that need to be trained.
In the context of ASR, convolutional models can capture local structure within sentences, thus allowing them to generate better, more accurate predictions.
How Rev’s Models Compare
The best part about the Rev ASR system is that because it’s trained on tens of thousands of hours of audio and transcripts from 50,000+ English speaking transcriptionists, the model excels on real world data, outperforming systems designed by the likes of Google, Amazon, and Microsoft. The thing is that a lot of the datasets used to evaluate ASR systems in research papers don’t translate well to real world applications.
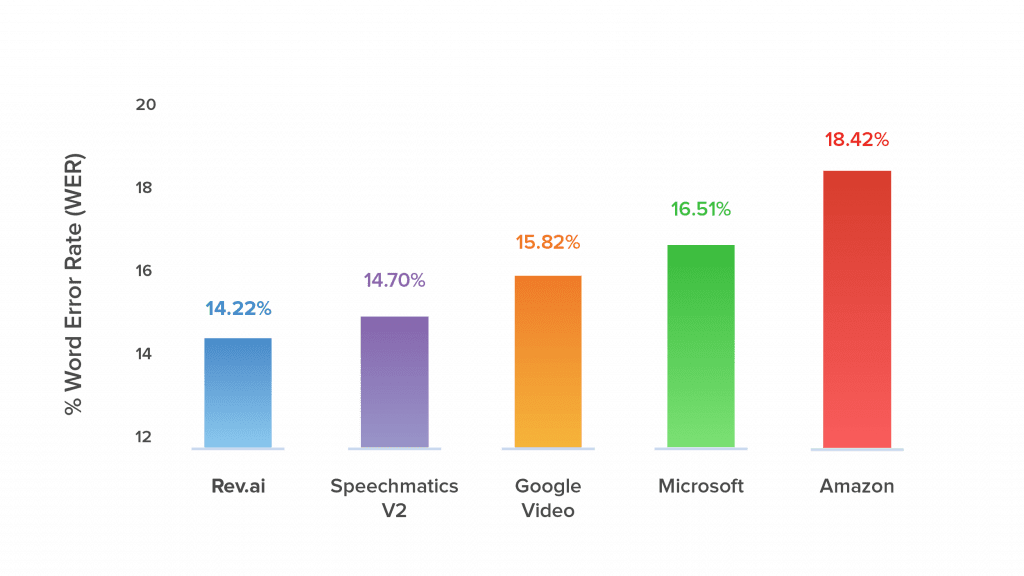
To get around this, Rev created a podcast challenge which evaluates speech recognition models against one of their most popular use cases – creating transcripts of podcast episodes. We then tested and compared our ASR engine against those from other companies using a test suite of 30 episodes comprising 27.5 hours of podcast audio that was not included in the original training set. We also included a wide diversity of episodes with varying signal-to-noise ratio in order to test the efficacy of the models when applied to audio of varying acoustic quality.
Finally, Rev used a custom tool for word error rate (WER) calculation and compared the error rates across different systems. Rev emerged as the clear winner, demonstrating the lowest error rate on 60 percent of the podcast episodes. Feel free to download and use this tool to validate the results or calculate Rev’s WER on your own audio against different speech recognition systems.





