
Featured Posts
.webp)
6 Free Incident Report Templates For Lawyers & More
Download Rev’s free incident report templates for personal injury, law enforcement, workplace accidents, and more. Plus, learn how to write one correctly.
.webp)
Free Case Brief Template For Lawyers And Law Students
Download a free case brief template and learn how to organize facts, holdings, and procedural history in order to prep faster and argue stronger.

AI in Policing: Benefits, Risks, and Real-World Use Cases
AI in policing is a complex and ever-evolving topic. Read up on risks, benefits, and how this tech is being used in real-world scenarios on Rev’s blog.

Bates Numbering Explained: Best Practices For Legal Doc Management
Learn everything you need to know about Bates numbering, formatting, and how to make your entire document workflow smoother and more defensible with Rev.

Finding Prior Inconsistent Statements In Real Time
Take a deep dive into the current strategies for finding witness inconsistencies during trial, and learn how tech like Rev is streamlining the review process.
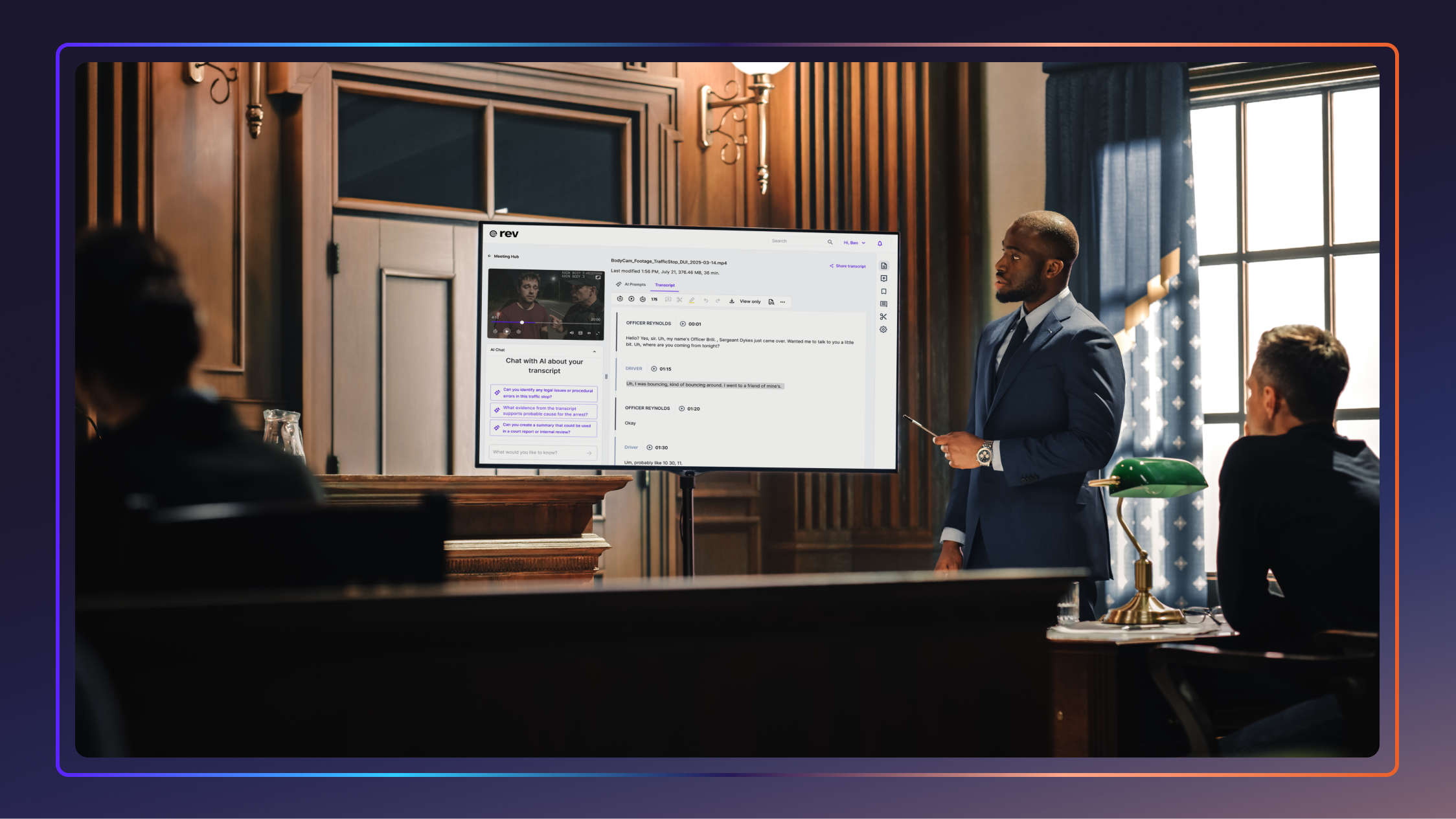
How Court Technology Is Changing Litigation Strategy
Modern court technology is transforming how attorneys prepare cases, manage evidence, and present arguments in court. Here are six key changes.

49 AI In Law Statistics: How Tech Is Changing The Industry
Check out over 48 key stats about AI in the legal industry, including how lawyers are using AI right now, public opinion, and where the tech is headed.

Different Learning Styles: Boost Student Participation
Rev breaks down different learning styles and how teachers can adapt their strategies to serve all their students.

New York Court Guideline: A New AI Ruling for Attorneys
The latest AI rule for courts went live in New York on 6/1/26. Here’s what you need to know about the new ruling, and how to use legal AI responsibly.

30 Famous Movie Speeches That Stand The Test of Time
We've rounded up 30 of the greatest movie monologues ever put on screen. Plus, full transcripts of each speech so you can relive your favorite moments.
.webp)
Mass Tort Intake: How To Scale Without Sacrificing Quality
Take a deep dive into mass tort cases, their intake process, and how your firm can update your strategies to take on high-volume cases with ease.

Medical Chronology: How To Create A Case-Changing Timeline
For personal injury lawyers, building a medical chronology is critical for settling claims or winning a trial. Learn how to create a case-changing timeline.

Understanding ADA Title III Compliance in Higher Education
Learn Title III ADA requirements for higher education, including accessibility rules, common violations, and practical steps to stay compliant.

Best Practices for Trial Prep in Personal Injury Cases
Learn the best practices for trial prep in personal injury cases, from evidence gathering to witness coaching, plus get a checklist to help you prep for trial.

Educational Technology Trends Shaping Higher Education
Edtech is no longer just a competitive advantage. For many institutions, it's a legal necessity. Learn more about the biggest trends shaping the industry.

16 Fourth Of July Speeches You Need To Know
Looking for patriotic inspiration? Read transcripts of the 16 best Fourth of July speeches to see how past presidents and leaders celebrated Independence Day.

20 Commencement Speech Examples That Inspired Generations
From Steve Jobs to Sheryl Sandberg, here are 20 of the best commencement speeches of all time. Plus, get tips on how to write a graduation speech of your own.
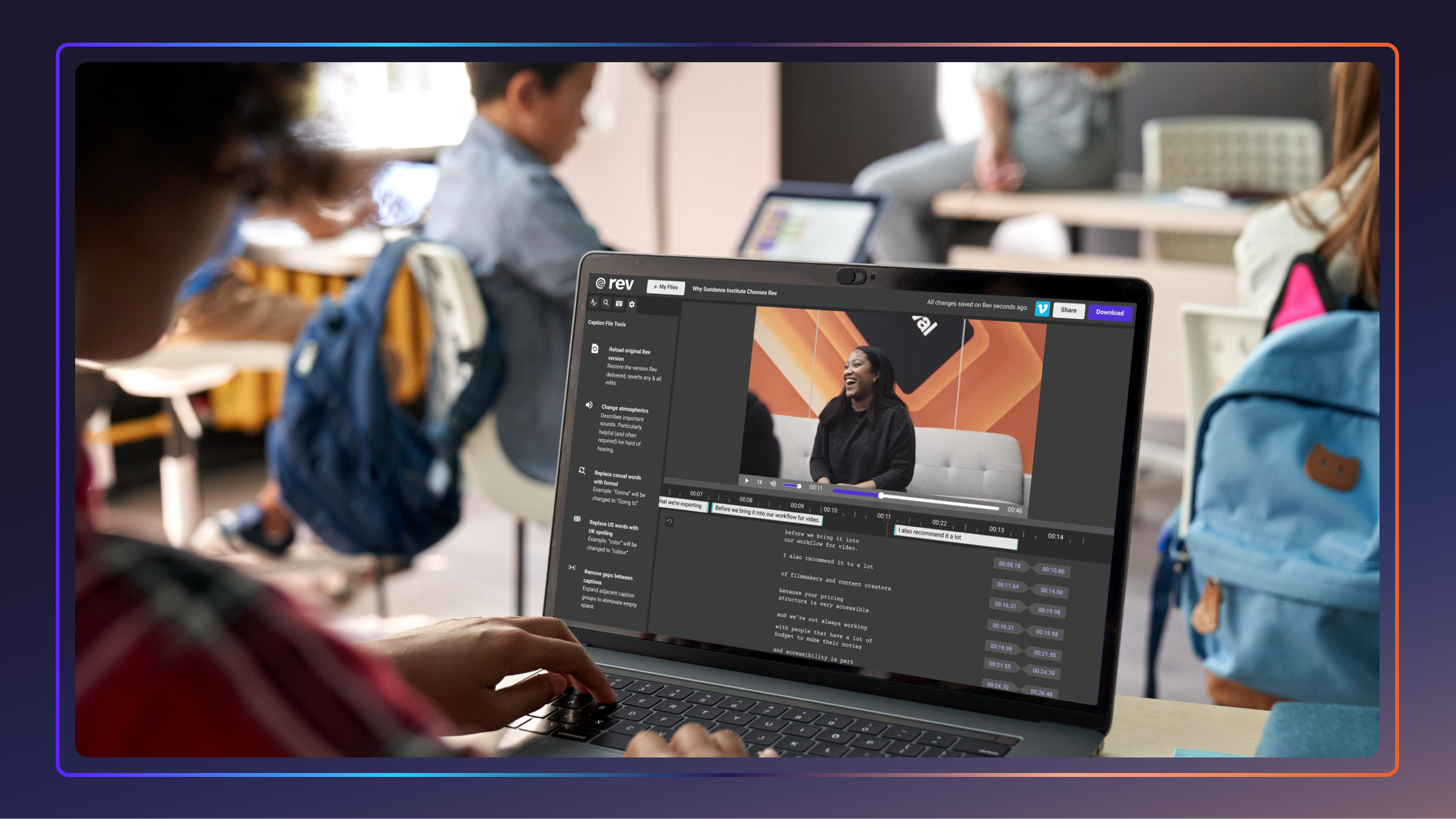
Video Accessibility Checklist For Schools + Universities
Learn how to make your educational video content accessible to all students and download our free video accessibility checklist to ensure ADA compliance.

Policy Limit Investigations + How To Maximize Recovery
Understand policy limit research in personal injury cases and learn how to identify coverage, strengthen strategy, and maximize recovery.

Courtroom Accessibility For A Just Legal System
Learn about modern approaches to courtroom access and the law, from ADA requirements to digital tools like transcripts and court records.

10 Legal AI Tools That Actually Help Lawyers
From evidence and contract analysis to research and drafting tools, these 10 legal AI tools will help you work faster without sacrificing accuracy.

Your Guide To Accessibility in Higher Education
With new accessibility deadlines looming, here’s Rev’s guide to getting your school, lectures, and learning materials up to ADA and WCAG guidelines.

ADA Website Compliance: What Site Owners Need to Know
Learn about upcoming ADA website compliance deadlines for schools, public agencies, and site owners. Plus, download our checklist to ensure your site is accessible.

The Real Impact of AI for Personal Injury Lawyers in 2026
From medical transcription to evidence analysis, AI for personal injury lawyers can streamline your workflow and raise your bottom line. Here’s how!
Free Case Brief Template For Lawyers And Law Students
Download a free case brief template and learn how to organize facts, holdings, and procedural history in order to prep faster and argue stronger.

Texas AI Law for Attorneys: Ethics Opinion 705 & TRAIGA
Learn more about Ethics Opinion 705, TRAIGA, and local Texas guidelines for using AI in legal settings with this guide from the experts at Rev.
Bates Numbering Explained: Best Practices For Legal Doc Management
Learn everything you need to know about Bates numbering, formatting, and how to make your entire document workflow smoother and more defensible with Rev.

Spoliation Of Evidence: Risks, Sanctions, & Prevention
Modern litigation depends on preserving digital evidence. Learn what spoliation means, when the duty to preserve begins, and how legal teams can avoid sanctions.
.webp)
Florida's New AI Citation Rule: What Every Attorney Needs to Know
On 6/15/26, Florida’s Supreme Court’s new AI citation ruling went into effect. Here is what it means for attorneys practicing within Florida’s state lines.
New York Court Guideline: A New AI Ruling for Attorneys
The latest AI rule for courts went live in New York on 6/1/26. Here’s what you need to know about the new ruling, and how to use legal AI responsibly.

Cybersecurity For Law Firms: How To Avoid A Breach
Learn how to improve your law firm’s cybersecurity with key threats, compliance rules, and 10 practical strategies to protect sensitive client data.

Reasonable Doubt: Definition, Burden, And Strategies
Understand what reasonable doubt means, the prosecution’s burden of proof, and how defense attorneys identify doubt in complex criminal trials.
.webp)
Best Harvey AI Alternatives for Attorneys (+Accuracy Comps)
The best legal AI tools help attorneys address specific needs, optimize firm workflows, and improve client cases. See how these Harvey AI competitors compare.

Legal Subscription Services Better Than ChatGPT Wrappers
Legal subscription services can’t just be ChatGPT in shiny wrappers; they need to truly understand and integrate with what attorneys need. Here’s our guide to the best.
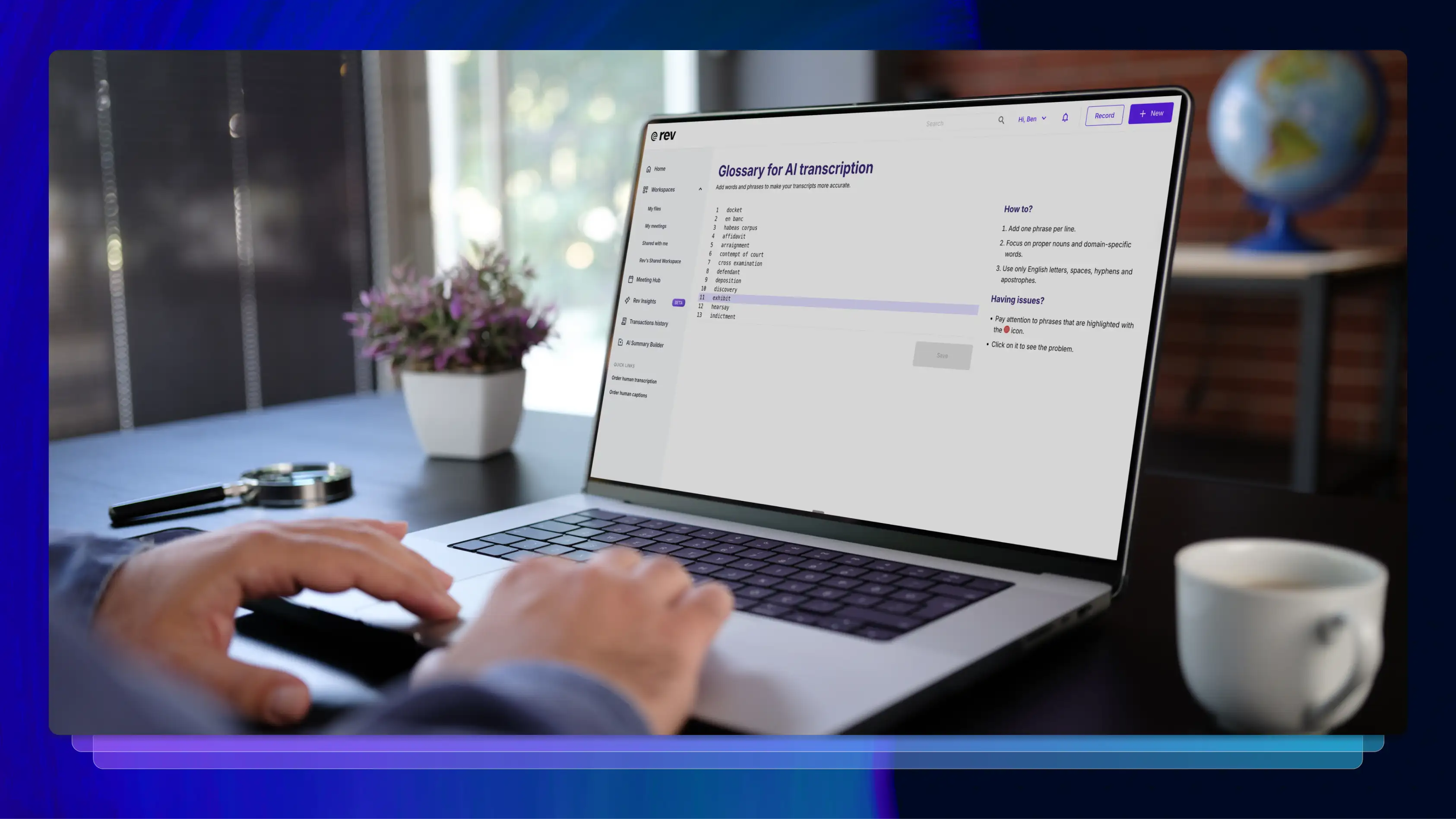
100+ Legal Terms + How A Transcript Glossary Improves Accuracy
Explore 100 essential legal terms and learn how Rev’s custom glossaries improve transcript accuracy, consistency, and efficiency for legal teams.
.webp)
11+ Legal Tech Conferences to Attend in 2026
Legal tech conferences can introduce your firm to new, cutting-edge technology that will help you deliver better results at a faster pace. Let’s look at some important upcoming law events.
Why Legal AI Needs Better AI Architecture, Not Generative Guesswork
Click to learn how closed-loop AI architecture can significantly reduce hallucination risk vs. generative AI guesswork in high-stakes legal work.

Your Data Stays Yours: Rev’s Commitment to Security
Rev's ironclad security ensures attorney-client privilege through SOC 2 Type II, HIPAA, and CJIS compliance, with zero third-party data training. Discover how we protect your legal information.
.webp)
How To Create a Paperless Legal Practice For Increased Efficiency
Creating a paperless legal practice can transform how efficiently you serve clients and prepare cases. Learn exactly how to do it here.

The Privacy Advantage: How Rev's Data Protection Sets Legal Professionals Apart
Discover why law firms trust Rev's SOC 2, HIPAA & GDPR-compliant platform. Zero third-party data sharing, no AI hallucinations, and ironclad attorney-client privilege protection.

The Legal Potential of Agentic AI
Explore how agentic AI is transforming legal practice with autonomous workflows—plus the critical security, accountability, and oversight risks lawyers must navigate.

How Law Enforcement Transcription Helps Justice Move Faster
Learn more about law enforcement transcription, including what it is, how it works, and the benefits for both law enforcement and legal defense teams.

AI Sentencing Ethics + The Future of Algorithmic Sentencing
AI sentencing tools promise efficiency but raise bias and fairness concerns. Learn what courts and lawyers need to know about algorithmic justice.
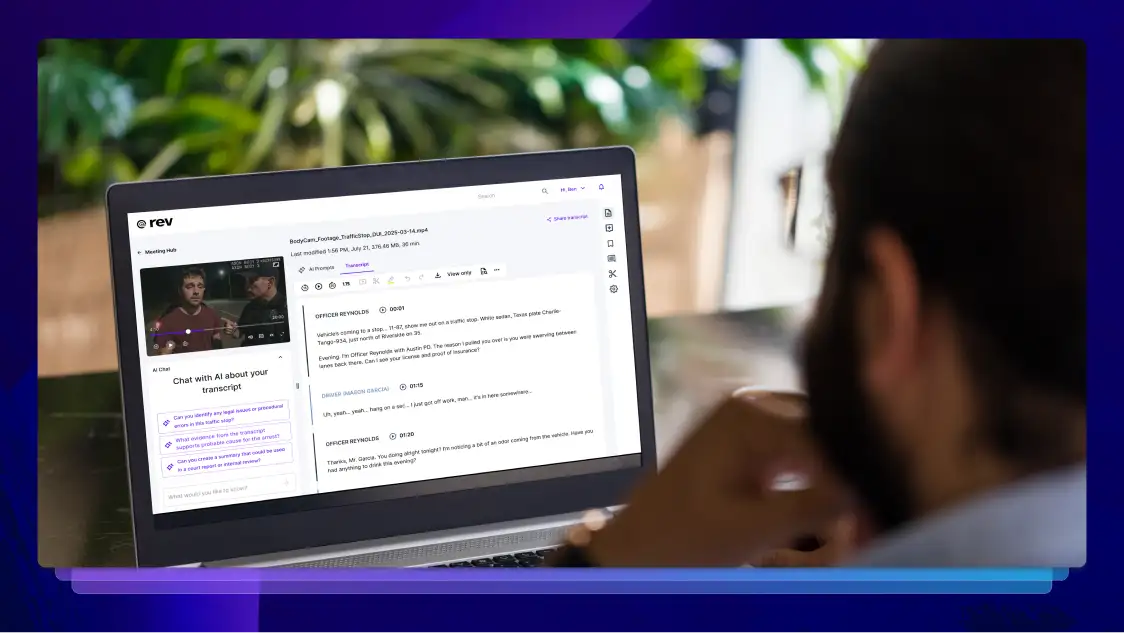
What Is Legal Transcription?
Legal transcription is a specialized form of typing that converts audio and video files into text. Here’s what you need to know, from the process to its benefits.

eDiscovery Project Management Tips + Tricks
Learn what eDiscovery project management involves, key frameworks like the EDRM, and tips paralegals can use to speed up discovery with technology.

AI for Legal Discovery: How to Improve the eDiscovery Process
Legal discovery is a critical yet time-consuming part of building a strong case. Here’s how paralegals can streamline the eDiscovery process with AI solutions.
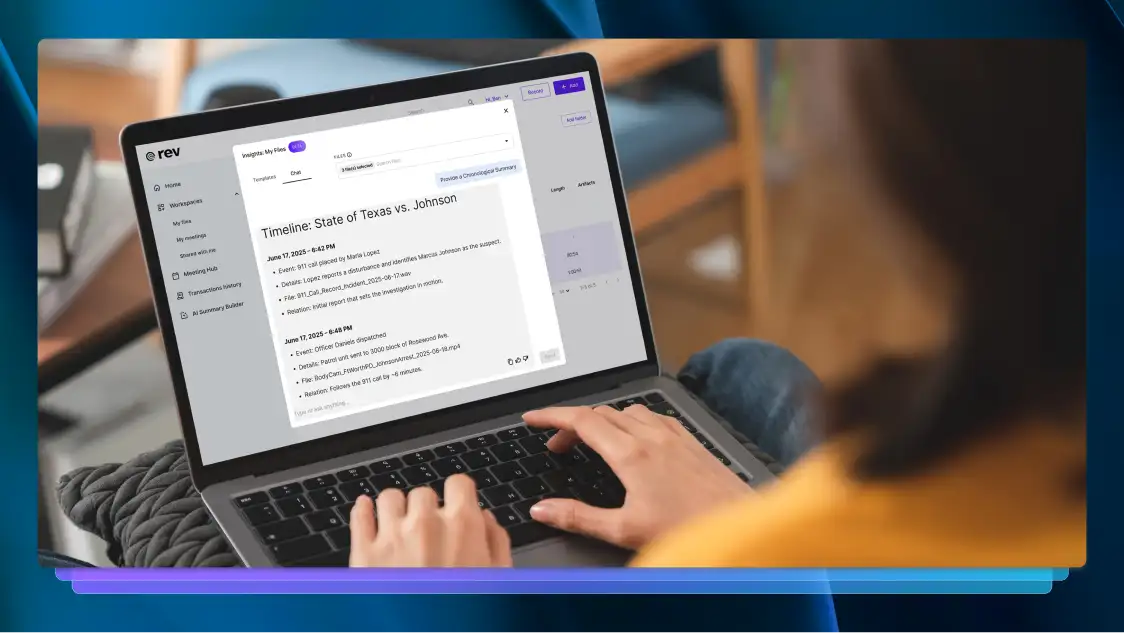
How to Create a Legal Timeline For Proper Case Chronology
Creating a strong legal timeline is key to building a winning case. Here are the steps paralegals should follow to create a proper case chronology.
.webp)
Everlaw vs Relativity (And What About Rev?)
Evaluating Everlaw vs Relativity: which eDiscovery platform wins out? Rev breaks the two services down and tells how we fill the gaps and support the entire process.
49 AI In Law Statistics: How Tech Is Changing The Industry
Check out over 48 key stats about AI in the legal industry, including how lawyers are using AI right now, public opinion, and where the tech is headed.

Survey: 48% Say AI In Legal Education Delivers An Advantage
New survey of legal pros shows AI's rise in legal education. Nearly half say it gives students a career edge, while accuracy and ethics outrank speed and cost.

49 Criminal Justice Statistics for the United States
The American criminal justice system is vast and ever-changing, with technology and reforms being introduced every day. Let’s look at some key criminal justice data.

54 Lawyer Statistics + Facts That Might Surprise You
Lawyer statistics ranging from demographics to legal technology to future trends are collected in this comprehensive look at 54 legal facts by Rev.

AI Is Everywhere in Law — and 68% of Lawyers Trust It With Sensitive Data
The majority of legal professionals use AI today, and a new Rev study shows 68% trust closed-loop systems with their sensitive client data. Click for more insights into the legal AI landscape.

Survey: 65% Use AI Legal Advice, But Accuracy Concerns Remain
New data reveals how Americans use AI for legal questions, why they still rely on lawyers, and what law firms can do now to build safer AI-ready workflows.

Heavy AI Users Face 3x More Hallucinations and Spend 10x Longer to Get Answers
Survey insights show heavy AI users face 3x more hallucinations, take 10x longer for satisfaction, and struggle most with AI prompting despite their experience.

85% Believe Prompting Will Be a Must-Have Job Skill in the AI Era
A new survey reveals Gen Z treats AI prompting as career prep, while employer training boosts efficiency 20%. See how generations approach this emerging job skill.
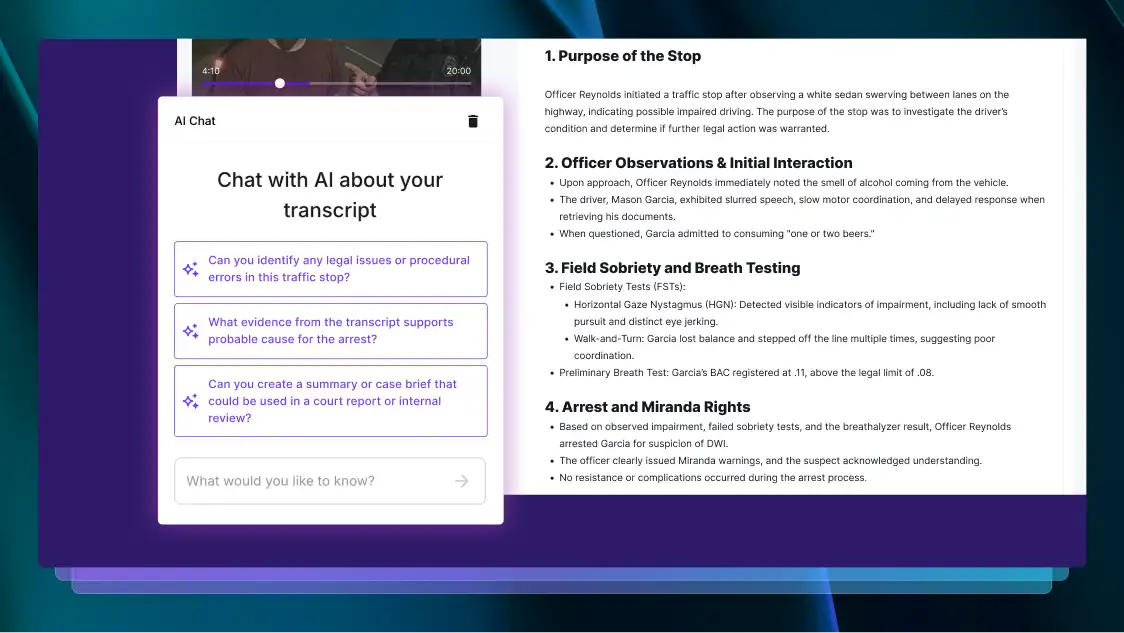
58+ Chatbot Statistics That Demonstrate The Future of AI
The popularity of AI chatbots for businesses and beyond doesn’t seem to be slowing down. Let’s look at some statistics that cover the popularity, use cases, and future of AI chatbots.

60% of Americans Get Their Legal Knowledge From Media Consumption
A new survey reveals what Americans think lawyers do, spotlighting the growing need for solutions that close the gap between legal reality and public perception.

4 in 5 Legal Professionals Are Burned Out: Can AI Be the Lifeline?
New report: 4 in 5 lawyers experience burnout. Learn how overwhelming workloads lead to stress and how AI is helping legal professionals find balance.

2025 Court Reporting Industry Trends: What Lawyers and CRAs Need to Know
Understand the stenographer shortage, the rise of digital solutions, and key insights from the AAERT report. Plus, learn how Rev’s tech can help.

The 2025 Legal Tech Survey
Discover key insights from Rev's comprehensive 2025 Legal AI Survey revealing how the profession is embracing AI.

Rev + ASR: An In-Depth Look
Explore key insights from Rev's State of ASR Report, highlighting accuracy, benchmark results, and trends in speech technology.

40 Meeting Statistics That Showcase New Trends in Meetings
Let’s look at some must-know meeting statistics to learn more about the advantages of meetings and when they’re unnecessary.

36 YouTube Stats, Facts, and Figures to Know in 2026
YouTube is one of the most influential social media platforms around. We’ve compiled some must-know YouTube stats to inform your strategy.

46 Video Marketing Statistics: What Is the State of the Industry In 2026?
How effective is video marketing? Discover key video marketing statistics—from engagement rates to ROI—to inform your 2026 strategy.

Rev Improves Accuracy by Over 30% with Launch of New v2 ASR Model
Rev's new automatic speech recognition (ASR) model is 25% more accurate than our existing model. Learn more about this technology today.

The Ultimate Roundup of Compelling Closed Captions Statistics
Whether you're looking to imrpove accessibility, boost SEO, or promote engagement, these statistics prove the benefits of closed captions.

AI Effects on Workforce Hearing
Senate HELP subcommittee holds hearing on AI’s effect on the workforce. Read the transcript here.


Fauci Congressional Hearing
The Senate Homeland Security Committee holds a hearing to take the testimony of Dr. Anthony Fauci. Read the transcript here.

Funeral for Lindsey Graham
Funeral service for Senator Lindsey Graham at Washington National Cathedral. Read the transcript here.

MA v. Lindsay Clancy Opening Statements
Opening arguments in the murder trial of Lindsay Clancy. Read the transcript here.

Trump Rally on 7/27/26 in Michigan
Donald Trump holds an event in Michigan on 7/27/26. Read the transcript here.

White House Correspondants Dinner
Donald Trump speaks at the White House Correspondents' Dinner. Read the transcript here.

Seattle Shooting Press Conference
Officials give an update on the Seattle Center shooting near the Space Needle. Read the transcript here.



Trump Rally Marietta, GA 7/22/26
Donald Trump delivers remarks at Wheeler High School in Marietta, Georgia. Read the transcript here.

Supplemental Funding Request Hearing
Pete Hegseth, Dan Caine, and Brooke Rollins testify on the President's June 24th supplemental funding request. Read the transcript here.

Tate Attorney Speaks to Press
Defense attorney Joseph McBride, representing Andrew and Tristan Tate, delivers a statement outside the courthouse. Read the transcript here.

Insider Trading Hearing
House Rules Committee holds a hearing on pending insider trading legislation. Read the transcript here.

Blanche Confirmation Day Two
Todd Blanche confirmation hearing for Attorney General, day two. Read the transcript here.

Blanche Confirmation Day One
Todd Blanche testifies at confirmation hearing to be Attorney General, day one. Read the transcript here.

Trump Address to the Nation 7/16/26
Donald Trump speaks to the nation on election integrity claims. Read the transcript here.

UT v. Tyler Robinson Preliminary Hearing Day 5
Day 5 of the UT v. Tyler Robinson Preliminary Hearing. Read the transcript here.
UT v. Tyler Robinson Preliminary Hearing Day 4
Day 4 of the UT v. Tyler Robinson Preliminary Hearing. Read the transcript here.

UT v. Tyler Robinson Preliminary Hearing Day 3
Day 3 of the UT v. Tyler Robinson Preliminary Hearing. Read the transcript here.

Update on High-Rise Collapse Risk
Zohran Mamdani gives an update as Manhattan buildings are evacuated over high-rise collapse risk. Read the transcript here.

78th Emmy Awards Nominations
Emmy winners Liza Colón-Zayas and Jeff Hiller announce the nominees for the 78th Emmy Awards. Read the transcript here.

UT v. Tyler Robinson Preliminary Hearing Day 2
Day 2 of the UT v. Tyler Robinson Preliminary Hearing. Read the transcript here.

Trump Meets Zelenskiy on Sidelines of NATO Summit
Donald Trump meets Ukrainian President Volodymyr Zelenskyy on the sidelines of a NATO summit in Ankara, Turkey. Read the transcript here.

UT v. Tyler Robinson Preliminary Hearing Day 1
Charlie Kirk's accused killer, Tyler Robinson, is in court as prosecutors begin a preliminary hearing. Read the transcript here.

America 250 Keynote Address
Donald Trump delivers the keynote address at America 250. Read the transcript here.

Mount Rushmore Speech
Donald Trump speaks at Mount Rushmore on the eve of America 250. Read the transcript here.

Northern Border Hearing
The Subcommittees on Border Security and Enforcement and Counterterrorism and Intelligence hold a hearing on the U.S. Northern Border. Read the transcript here.

Sanctuary Cities Congressional Hearing
House Judiciary Subcommittee on Immigration Integrity, Security, and Enforcement holds a hearing on Sanctuary City policies. Read the transcript here.

Tren de Aragua Press Conference
Todd Blanche and Kash Patel hold a press conference on the takedown of the Venezuela Gang, Tren de Aragua. Read the transcript here.

Actor Sean Astin Testifies in IP Protection Hearing
Actor Sean Astin testifies before Congress about Intellectual Property protection in the Digital Age. Read the transcript here.

MKUltra Congressional Hearing
Lawmakers probe the CIA's MKUltra and Mind Control programs in House Oversight Committee. Read the transcript here.

Right to Fix Executive Order
Donald Trump signs an executive order pertaining to auto repairs. Read the transcript here.

Murdaugh Retrial Pretrial Hearing
Alex Murdaugh is back in court for a pretrial hearing ahead of his retrial. Read the transcript here.

House DHS Hearing
DHS Secretary Markwayne Mullin testifies before the House Appropriations Committee. Read the transcript here.

House Hearing on Medicaid Fraud
The House Energy & Commerce Subcommittee on Oversight and Investigations holds a hearing on Medicaid fraud. Read the transcript here.
Subscribe to The Rev Blog
Sign up to get Rev content delivered straight to your inbox.