The 5 Best Open Source Speech Recognition Engines & APIs
There are many open-source speech recognition systems and APIs to choose from. Click to see our top five for converting speech to text.
In this article, we provide a breakdown of five of the best free-to-use open source speech recognition services along with details on how you can get started.
1. Mozilla DeepSpeech
DeepSpeech is a Github project created by Mozilla, the famous open source organization which brought you the Firefox web browser. Their model is based on the Baidu Deep Speech research paper and is implemented using Tensorflow (which we’ll talk about later).
Pros of Mozilla DeepSpeech
- They provide a pre-trained English model, which means you can use it without sourcing your own data. However, if you do have your own data, you can train your own model, or take their pre-trained model and use transfer learning to fine tune it on your own data.
- DeepSpeech is a code-native solution, not an API. That means you can tweak it according to your own specifications, providing the highest level of customization.
- DeepSpeech also provides wrappers into the model in a number of different programming languages, including Python, Java, Javascript, C, and the .NET framework. It can also be compiled onto a Raspberry Pi device which is great if you’re looking to target that platform for applications.
Cons of Mozilla DeepSpeech
- Due to some layoffs and changes in organization priorities, Mozilla is winding down development on DeepSpeech and shifting its focus towards applications of the tech. This could mean much less support when bugs arise in the software and issues need to be addressed.
- The fact that DeepSpeech is provided solely as a Git repo means that it’s very bare bones. In order to integrate it into a larger application, your company’s developers would need to build an API around its inference methods and generate other pieces of utility code for handling various aspects of interfacing with the model.
2. Wav2Letter++
The Wav2Letter++ speech engine was created in December 2018 by the team at Facebook AI Research. They advertise it as the first speech recognition engine written entirely in C++ and among the fastest ever.
Pros of Wav2Letter++
- It is the first ASR system which utilizes only convolutional layers, not recurrent ones. Recurrent layers are common to nearly every modern speech recognition engine as they are particularly useful for language modeling and other tasks which contain long-range dependencies.
- The authors also released a more general purpose machine learning library called Flashlight which Wav2Letter++ is a part of. It too is written entirely in C++ and enables fast, highly optimized computations on both the CPU and GPU.
- Within Wav2Letter++ the code allows you to either train your own model or use one of their pretrained models. They also have recipes for matching results from various research papers, so you can mix and match components in order to fit your desired results and application.
Cons of Wav2Letter++
- The downsides of Wav2Letter++ are much the same as with DeepSpeech. While you get a very fast and powerful model, this power comes with a lot of complexity. You’ll need to have deep coding and infrastructure knowledge in order to be able to get things set up and working on your system.
3. Kaldi
Kaldi is an open-source speech recognition engine written in C++, which is a bit older and more mature than some of the others in this article. This maturity has both benefits and drawbacks.
Pros of Kaldi
- On the one hand, Kaldi is not really focused on deep learning, so you won’t see many of those models here. They do have a few, but deep learning is not the project’s bread and butter. Instead, it is focused more on classical speech recognition models such as HMMs, FSTs and Gaussian Mixture Models.
- Kaldi methods are very lightweight, fast, and portable.
- The code has been around a long time, so you can be assured that it’s very thoroughly tested and reliable.
- They have good support including helpful forums, mailing lists, and Github issues trackers which are frequented by the project developers.
- Kaldi can be compiled to work on some alternative devices such as Android.
Cons of Kaldi
- Because Kaldi is not focused on deep learning, you are unlikely to get the same accuracy that you would using a deep learning method.
4. Open Seq2Seq
Open Seq2Seq is an open-source project created at Nvidia. It is a bit more general in that it focuses on any type of seq2seq model, including those used for tasks such as machine translation, language modeling, and image classification. However, it also has a robust subset of models dedicated to speech recognition.
The project is somewhat more up-to-date than Mozilla’s DeepSpeech in that it supports three different speech recognition models: Jasper DR 10×5, Baidu’s DeepSpeech2, and Facebook’s Wav2Letter++.
Pros of Seq2Seq
- The best of these models, Jasper DR 10×5, has a word error rate of just 3.61%.
- The Open Seq2Seq package provides some nice features such as support for multi-GPU and distributed training as well as mixed precision training.
- Note that the models do take a fair amount of computational power to train. They estimate that training DeepSpeech2 should take about a day using a GPU with 12 GB of memory.
Cons of Seq2Seq
- One negative with Open Seq2Seq is that the project has been marked as archived on Github, meaning that development has most likely stopped. Thus, any errors that arise in the code will be up to users to solve individually as bug fixes are not being merged into the main codebase.
5. Tensorflow ASR
Tensorflow ASR is a speech recognition project on Github that implements a variety of speech recognition models using Tensorflow. While it is not as well known as the other projects, it seems more up to date with its most recent release occurring in just May of 2021.
The author describes it as “almost state of the art” speech recognition and implements many recent models including DeepSpeech 2, Conformer Transducer, Context Net, and Jasper. The models can be deployed using TFLite and they will likely integrate nicely into any existing machine-learning system which uses Tensorflow. It also contains pretrained models for a couple of foreign languages including Vietnamese and German.
What Makes Rev AI Different
While open-source speech recognition systems give you access to great models for free, they also undeniably make things complicated. This is simply because speech recognition is complicated. Even when using an open-source pre-trained model, it takes a lot of work to get the model fine-tuned on your data, hosted on a server, and to write APIs to interface with it. Then you have to worry about keeping the system running smoothly and handling bugs and crashes when they inevitably do occur.
The great thing about using a paid provider such as Rev is that they handle all those headaches for you. You get a system with guaranteed 99.9+% uptime with a callable API that you can easily hook your product into. In the unlikely event that something does go wrong, you also get direct access to Rev’s development team and fantastic client support.
Another advantage of Rev is that it’s the most accurate speech recognition engine in the world. Their system has been benchmarked against the ones provided by all the other major industry players such as Amazon, Google, Microsoft, etc. Rev comes out on top every single time with the lowest average word error rate across multiple, real-world datasets.
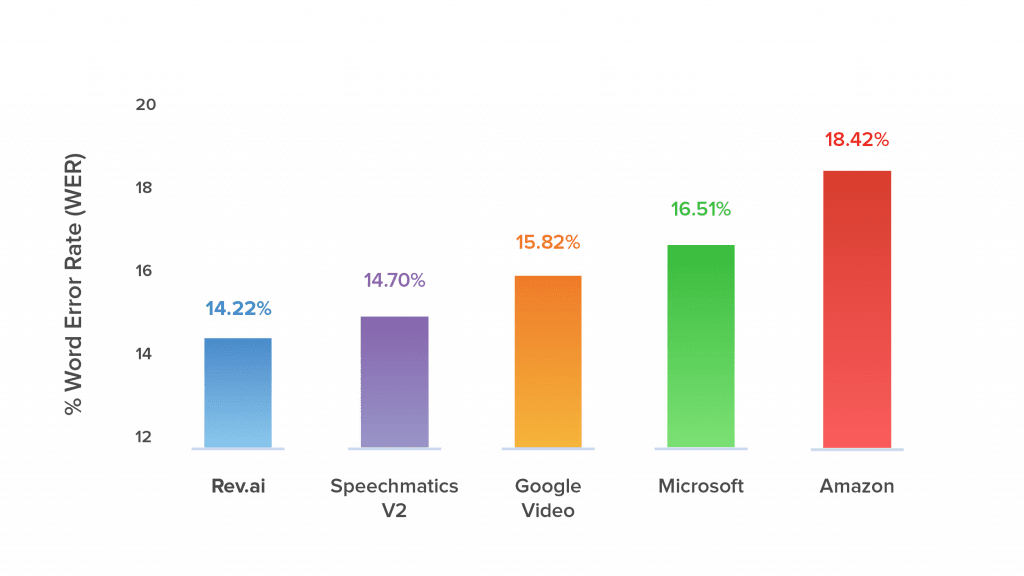
Finally, when you use a third-party solution such as Rev, you can get up and running immediately. You don’t have to wait around to hire a development team, to train models, or to get everything hosted on a server. Using a few simple API calls you can hook your frontend right into Rev’s ASR system and be ready to go that very same day. This ultimately saves you money and likely more than recoups the low cost that Rev charges.



Subscribe to The Rev Blog
Sign up to get Rev content delivered straight to your inbox.