An Expert Guide to Automatic Speech Recognition Technology
Understand automatic speech recognition (ASR), how speech recognition AI works, and why accuracy is critical in high-stakes industries.

Over the past few decades, computers have gotten progressively better at processing human speech. When you dictate a text message or ask Spotify to play your favorite playlist, the accuracy of the result all depends on how your device interprets your request. And that starts with automatic speech recognition (ASR), which is the AI technology that transforms spoken words into text.
Today, ASR powers more than everyday convenience. Speech recognition AI also helps businesses capture information, make informed decisions, and keep precise records. From courtrooms and newsrooms to hospitals and customer support teams, organizations rely on ASR transcription to turn audio into usable, searchable text.
In this guide, we’ll break down what automatic speech recognition is, how it works today, and some of its most common uses. We’ll also look at why ASR accuracy matters, how Rev’s speech recognition software compares to other solutions on the market, and where this tech is headed next.
What Is Automatic Speech Recognition?
Automatic speech recognition is an AI-powered technology that converts spoken language into readable text. It’s built into tools people use every day — powering voice dictation, automated captions, meeting transcripts, virtual assistants, call analytics, and other speech-to-text applications.
ASR has advanced considerably since its earliest iterations, which could only recognize a small set of predefined words or commands within predictable settings. Today’s speech recognition technology is far more advanced, allowing organizations to transcribe natural, conversational, and even technical speech from a range of accents, speaking styles, and audio conditions.

What About Natural Language Processing?
Natural language processing (NLP) is a branch of artificial intelligence focused on understanding, analyzing, and generating written human language. While it’s sometimes confused with ASR, the two technologies are built for different tasks.
ASR turns spoken words into text, but NLP extracts meaning by summarizing content, answering questions, or even interpreting the emotions behind the words.
Although they’re separate technologies, ASR and NLP often work together. ASR creates the written transcript, and NLP tools evaluate or transform it for search, review, classification, or automation. Accurate ASR provides the foundation for NLP, and errors in speech-to-text conversion can carry through to every system that depends on that output.
How Does Automatic Speech Recognition Technology Work?
At the most basic level, ASR works by breaking down spoken audio into smaller pieces, studying patterns in those sounds, and converting them into written words. Although today’s ASR systems are far more advanced than decades-old models, the goal has always been to help computers reliably recognize speech, account for context, and produce accurate transcripts.
Here’s how automatic speech recognition technology works in practice:
1. From Sound Waves to Speech Data
Like any other sound, human speech forms an audio signal made up of sound waves. Humans interpret the words in those audio signals directly, but ASR systems use computational linguistics to analyze them and find patterns — vowels, consonants, pauses, etc. — that represent different speech sounds.
This is essential because real-world audio is rarely perfect. Background noise, competing voices, and microphone quality can all interfere with capturing a clear recording of speech. A high-quality ASR system zeroes in on the parts that matter most, separating speech from noise to isolate spoken words.
2. Turning Sounds Into Words
Once a speech recognition system has broken down speech into common sound patterns, it will use voice recognition deep learning — AI models extensively trained on real-world speech — to match those sounds to words it has learned from large volumes of training data. Instead of relying on a single guess, the system compares multiple possibilities and chooses the most likely words based on how it knows that people actually speak.
Context helps with those choices. Modern ASR systems compare how words typically appear together in natural conversation, which minimizes mistakes caused by similar-sounding words or unclear audio. This end-to-end approach (E2E), built on machine learning, allows today’s speech recognition technology to handle accents, conversational speech, and less-than-ideal recording conditions more effectively than earlier systems.
3. Speaker Diarization: Knowing Who Said What
Speaker diarization is the process that an ASR system uses to identify when different people are speaking and label those changes in a transcript. Instead of producing an unbroken block of text, diarization separates conversations into distinct speakers to make the transcript easier to read.
This is especially important in multi-speaker settings like meetings, interviews, depositions, and hearings. When you can clearly tell at a glance who said what, your transcripts become a more helpful, scannable record.
The Importance of ASR Accuracy
As ASR becomes more common in business settings that demand precision — like court proceedings, compliance documentation, and investigative reporting — accuracy has become a critical requirement. In a time when deepfake audio and misinformation abound, transcripts must be reliable records of fact, with accuracy that can be clearly measured and demonstrated.
ASR accuracy is measured by calculating the Word Error Rate (WER), which is the percentage of words the ASR transcribes incorrectly. A lower WER indicates greater accuracy, so it’s critical to get that number down in exacting industries such as legal, medical, or media.
In the legal field, for instance, small transcription errors can change the meaning of testimony, confuse who said what, or introduce uncertainty into official records. This makes independent benchmarking critical, as it shows that ASR performance differs noticeably across providers, the audio conditions, and industry context
Rev’s technology is a consistent leader in this area. According to an independent 2024 ASR benchmark study that evaluated nine leading ASR providers, Rev regularly achieved a lower WER than major competitors across a range of real-world scenarios, including noisy environments, far-field recordings, and telephone audio. Rev scored the highest marks in legal and journalistic settings, outperforming every other ASR provider tested, including OpenAI, Google, and Otter.
“In the past few years at Rev, we've taken to task to improve the way our ASR outputs ‘formatted words’ (capital letters, phone numbers, acronyms, etc), the way it punctuates sentences, the accuracy of "rare words", and to make the output much more readable,” says Miguel Jette, vice president of AI at Rev.
“In a way, the final frontier in ASR, in many cases, is around formatting, readability, and very specific industry jargon and rare words (pronouns, city names, company names, etc). Rev not only offers their ASR model as part of an enterprise-grade API (Rev AI) but also uses it internally to drive productivity of our system and to form the foundation of our SaaS platform.”
Use Cases for Speech Recognition AI
While ASR use is growing across a range of industries, some rely more heavily on the technology than others. Common uses for ASR AI tools include:
- Legal: Law firms, courts, and legal teams use ASR to transcribe depositions, hearings, and recorded proceedings. Accurate and searchable transcripts support case preparation, discovery, compliance, and record-keeping.
- Healthcare: Medical professionals use ASR to document clinical notes, transcribe patient encounters, and support telehealth workflows. Speech recognition software helps clinicians spend fewer hours on paperwork and more time with patients.
- Business: Small startups, growing businesses, and large enterprises can use ASR to transcribe meetings, calls, and presentations, making conversations searchable and easier to review. Fast, accurate transcripts serve as a foundation for summaries and knowledge sharing.
- Media and content creation: Journalists and creators have saved countless hours using ASR to quickly transcribe interviews, generate captions, and produce accessible content. Accurate speech-to-text is essential for quoting sources correctly and publishing on tight deadlines.
- Customer service: In call center environments, ASR enables conversation analysis, quality assurance, and training. Transcribed calls help organizations spot trends and resolve customer concerns more efficiently.
- Education: ASR supports lecture transcription, real-time captions, and accessible learning materials. Students and educators benefit from searchable transcripts that make reviewing and studying easier.
- Translation: ASR provides foundational support for translation providers, converting spoken words into text that can be easily processed. This helps break down language barriers in travel, global collaboration, and cross-border communication.
- Software development: Software teams use ASR APIs to add speech-to-text and voice-enabled features to applications without building models from scratch. Developers can create more intuitive, hands-free user experiences while reducing development time and overhead.
- Smart devices: ASR powers voice interaction in smart home devices and the entire Internet of Things (IoT). Voice commands allow users to control devices, access information, and automate tasks without screens or manual inputs.
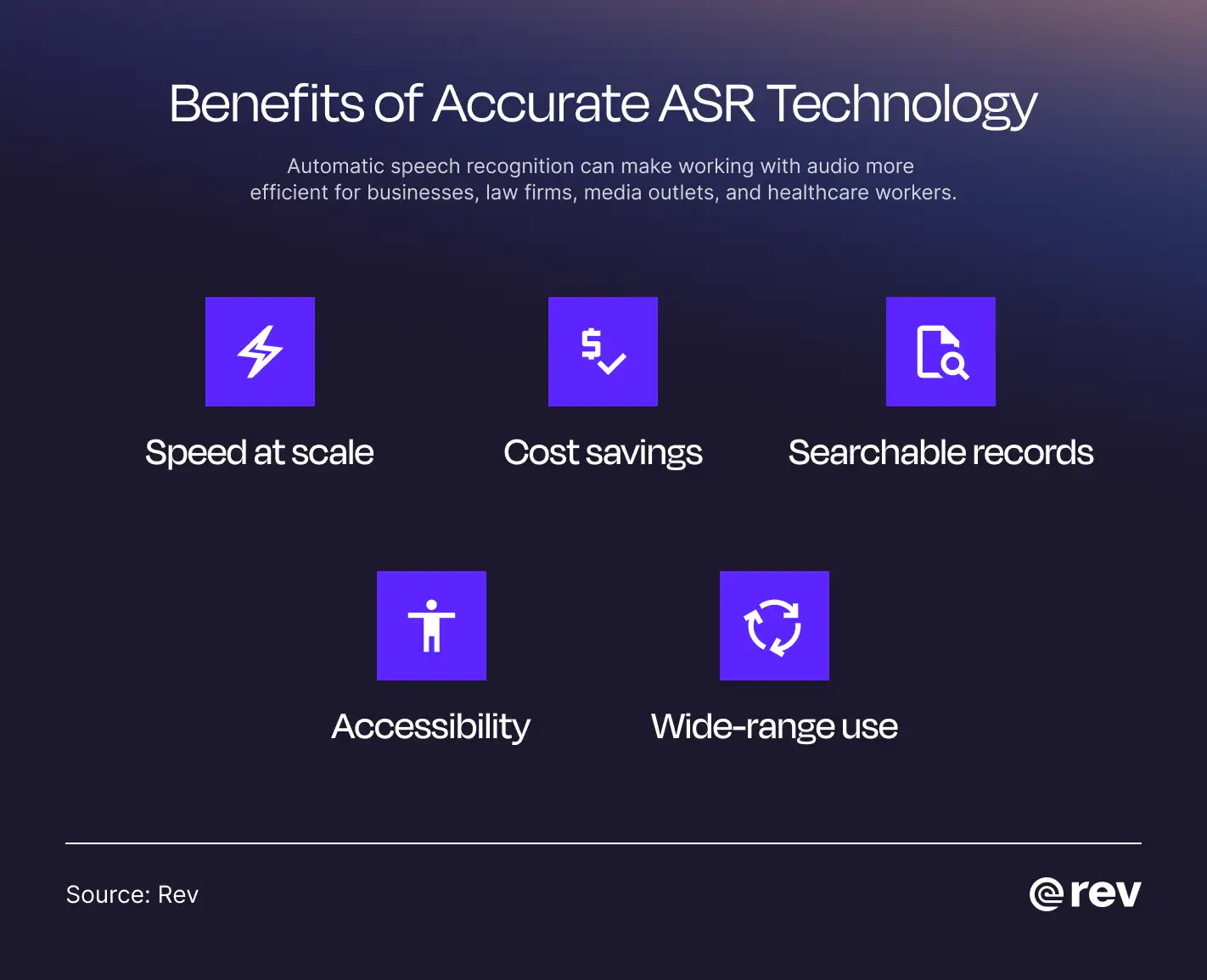
ASR Benefits
When used carefully, automatic speech recognition can make working with audio much more efficient. Organizations that rely on ASR gain benefits like:
- Speed at scale: In terms of speed, there’s simply no competition between human and AI speech-to-text. ASR can transcribe hours of meetings, interviews, legal proceedings, or calls in minutes, helping teams keep up without bottlenecks.
- Cost savings: Even when paired with human review, ASR dramatically reduces the time required to turn speech into usable text. The more audio your organization handles, the greater the efficiency gains — and cost savings — tend to be.
- Searchable, reusable records: Written content is far more searchable than audio. ASR turns recordings into searchable, shareable resources that support compliance, training, strategy, and long-term knowledge management.
- Better accessibility: ASR makes it easier to generate captions and transcripts that improve accessibility for deaf and hard-of-hearing audiences, as well as for people who prefer to read rather than listen.
- Support for other AI-powered tasks: Once speech is converted into text, AI tools can more easily summarize conversations, analyze patterns, and provide deeper insights.
ASR Drawbacks
Even with the great strides the tech has taken in recent years, automatic speech recognition isn’t a foolproof tool. As the tech and its many use cases evolve, so do the risks of mishandling it. Without appropriate checks, ASR brings drawbacks such as:
- Mixed accuracy: Background noise, overlapping speakers, poor microphones, and distance from the speaker can all affect transcription quality. Even advanced ASR systems may have a hard time with imperfect audio. In sensitive use cases such as legal or medical contexts, it’s still important to pair ASR results with human review.
- Bias and inclusivity concerns: Despite major improvements, speech recognition technology still shows uneven results among diverse speaker types. Recent research from Georgia Tech found that ASR models produce higher error rates for speakers using minority English dialects, such as African American Vernacular English. These systems require much more varied training data to overcome these built-in biases.
- Data confidentiality and security risks: Audio recordings often contain sensitive or personally identifiable information. If not properly secured, they can be vulnerable to unauthorized access or data exposure. To steer clear of any unintended exposure from these tools, carefully evaluate how the provider handles data storage, processing, and model training.
- Consistently evolving language: Slang, new terminology, and industry-specific language change constantly, and ASR systems must continually adapt to keep up with how people actually speak.
How ASR Will Transform the Future
As AI-powered ASR technology becomes the default for organizations, accuracy will matter more than ever. The public is growing increasingly wary of misinformation and manipulated audio. In the legal field and other high-stakes settings, this raises the bar for how speech recognition tools are built and refined.
Going forward, ASR development will likely be focused on improving performance in a range of challenging conditions, from noisy environments to natural, unscripted conversation. A bigger emphasis will also be put on more inclusive training data, and independent benchmarking will help define where systems still need improvement.
Advances in ASR are enabling progress in areas outside transcription. Affective computing, for example, looks at how something is said, not just what is said. Factors like tone, pacing, pauses, and emphasis can provide important context in areas such as emergency response, customer interactions, and investigative work. As ASR becomes more accurate, these signals can be analyzed more reliably and responsibly.
“Right now, people are exploring models that do not rely on self-attention anymore, to get rid of the compute-intensive nature of these models and enable much longer context when training them(and when doing inference),” Jette says. “But every direction will be improved: better at many languages, many accents, many audio contexts, smaller and faster models, and more.”
To sum it up, ASR will form the foundation for search, analysis, and automation of all kinds. As these systems scale, precision and transparency will be the key markers that determine whether ASR bolsters or weakens trust.
Setting the Standard for ASR Transcription
Automatic speech recognition technology is here to stay, and it’s getting better every year. As organizations rely more heavily on transcripts for search, analysis, and making decisions, accuracy and trust become non-negotiable.
With more than 12 years of experience collecting and transcribing speech data, and over 759 billion words transcribed in 2025 alone, Rev equips ASR models to handle the most complex speech-to-text tasks, especially in legal, media, and enterprise environments. We have always led the pack in thinking critically about how to improve these tools — and our industry-leading WER proves it.