




What is a Lexicon in Speech Recognition?
The lexicon is an important component in automatic speech recognition systems. It helps distinguish linguistics like accents and similar sounding words & phrases.
A key part of any automatic speech recognition system is the lexicon. The lexicon can be tricky to define because it’s sometimes used to mean different things depending on the context. In its most basic form, a lexicon is simply a set of words with their pronunciations broken down into phonemes, i.e. units of word pronunciation.
In many ways it is like a dictionary for pronunciation. The other way that the word lexicon is used is to refer to the finite state transducer which results from the lexicon preparation, sometimes referred to as “L.FST”. A finite state transducer is a finite state automaton which maps two sets of symbols together. In the case of the lexicon, such a transducer maps the word symbols to their respective pronunciations.
Defining the FST
The lexicon can be viewed as a Finite State Transducer along with a set of transition probabilities which specify the probability of transitioning between word phoneme states. The classic setup for this is to assign one state to each phoneme. Then, the probabilities of transitioning between states are specified by phoneme likelihoods, usually computed from some large corpus.
However, in many practical cases, we actually desire a more granular representation of phonemes. This is because phones can vary widely in length, lasting up to one second, and also in acoustic energy. Even between speakers, the length of a fixed phone can vary by up to 40-130 times. What’s more, certain sounds such as consonants and diphthongs have large variations in their acoustic waveforms.
For this reason, it doesn’t make sense to average the energy over the entire phone as this leads to a loss of information. Thus, many times we will assign three states per phone – a beginning, middle, and end state. This allows the model to capture information related to the varying acoustic energies within the phone. Additionally, “blank” phone states can be added to capture silence in between sequences of speech.
Variations in Spelling and Pronunciation
The reason why the lexicon is such an important piece of the speech recognition pipeline is because it gives a way of discriminating between different pronunciations and spellings of words. Many word components which are spelled the same have different pronunciations in different contexts.
For example, consider “ough” as in through, dough, cough, rough, bough, thorough, enough, etc. The pronunciation cannot be known from the spelling. In this case, the correct pronunciation for a given word will be determined contextually from the lexicon and the state transition probabilities which it encodes between word/phoneme states.
In other cases, even where the spelling of the word is the same, the pronunciation cannot be readily inferred. Take the case of the word “neural” which can be pronounced either as N UR UL or N Y UR UL depending on which part of the country you are from. For tricky edge cases like these, a quality lexicon will encode both pronunciation variants as well as give some probability as to the likelihood of each.
Finally, there can be variations of pronunciation within even the same speaker which can be attributed to how fast they’re talking or even just simple slips of the tongue. An example of this might be a shortening of a word such as when “accented” is pronounced without the T during rapid speech (AE K S EH N IH D). Another example might be an elision of words such as “New Orleans” being pronounced as “n’orleans” or “nawlins”. Thus, the lexicon can be important for representing other pronunciation phenomena that help deal with real speech in the wild.
How the Lexicon Is Used
The lexicon is a key part of the acoustic model. The entire acoustic model is defined by taking the lexicon pronunciation HMM and adding to it the cepstral feature vectors computed from the raw audio file. All told, the acoustic model is used to measure

Then, when combined with a language model, which estimates the prior probability,

, of a word in the source language. When these two models are used in conjunction, we can then execute a decoding procedure using the Baum-Welch and Viterbi algorithms to compute the posterior probability

which gives us the probability of any sequence of words given our observation of the raw audio file. By taking the sequence that maximizes this probability, we have effectively performed speech recognition.
Lexicon Resources
So how do we, for each word, get its constituent phones? Well, if you’re a linguist, you can author such a set yourself. However, for the vast majority of us it’s better to download an open source lexicon. One of the most popular such resources is the CMU Pronouncing Dictionary, often abbreviated as CMUdict. This resource contains four files: a set of 39 phone (phoneme) symbols as defined in ARPABET, a file containing the assignment of these symbols to their type, such as “vowel”, “fricative”, “stop”, or “aspirate”, a file giving pronunciations of various punctuation marks, and then the core dictionary giving pronunciations of standard English words, broken down by phone. Here is an example entry taken from that dictionary in order to give you an idea of what the data looks like:
abalone AE2 B AH0 L OW1 N IY0
As you can see, it has the word “abalone” broken down into its constituent sounds. Such a file would get fed into the ASR to create the lexicon HMM as described in the first section.
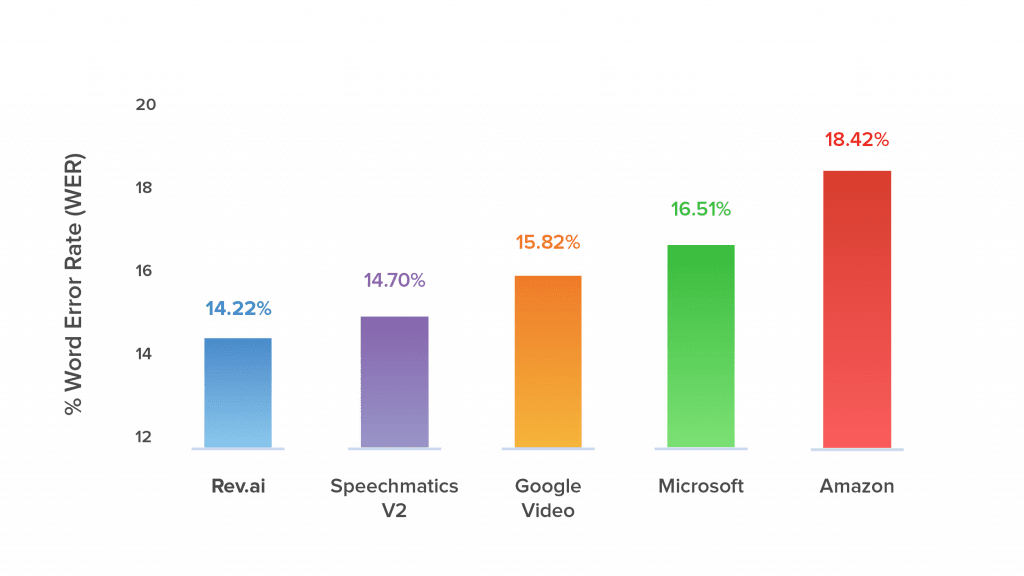
Rev AI Speech Recognition Accuracy
Due to the amount of raw data transcribed by Rev’s 60,000+ human professional transcriptionists, Rev has the most accurate speech recognition system and speech-to-text API. Rev consistently beats Google, Amazon, and Microsoft in accuracy tests.


Subscribe to The Rev Blog
Sign up to get Rev content delivered straight to your inbox.